
当咱们辩驳东谈主工智能的发展时,大大齐东谈主可能会合计这是一个远方而复杂的手艺鸿沟。但骨子上,AI老师经由中遭遇的许多问题,就像咱们日常生计中遭遇的学习难题一样毛糙易懂。这项由香港科技大学、萨里大学、香港大学和英伟达公司连合完成的猜想,发表于2026年3月的一篇预印本论文(编号:arXiv:2603.05369v1),为咱们揭示了一个看似毛糙却极其迫切的发现:让AI模子像东谈主类学习一样"循序渐进",竟然能大幅升迁学习效劳。
追溯咱们我方的学习资格,无论是学习钢琴照旧掌合手一门外语,咱们老是从基础入手,渐渐深入。比如学钢琴时,咱们先进修左手的基本和弦,等熟练后再加入右手旋律,临了才能演奏出齐全的乐曲。要是一入手就条件双手并用演奏复杂曲目,终结频频是一团糟。
当代AI模子的结构就像一座高楼,由许多层"楼层"堆叠而成。每一层齐像是一个成心的处理车间,负责谐和和加工从前一层传递过来的信息。但是,传统的老师时势就像让悉数楼层同期开工竖立,这样自然看似高效,骨子上却容易形成繁杂。底层的"地基"还没踏实,表层就入手施工,终结不言而喻。
这个问题在AI鸿沟被称为老师不稳定性。零散是当模子变得越来越深、越来越复杂时,这种不稳定性就像在薄冰上盖屋子一样危急。模子可能在老师经由中倏得"坍塌",或者学习效劳极其低下,就像一个班级里悉数学生齐在同期高声究诘不同问题,谁也听不清谁在说什么。
猜想团队淡薄的处分决策被称为"渐进式残差预热"(Progressive Residual Warmup,简称ProRes)。这个名字听起来很手艺化,但其中枢想想却相当朴素:让AI模子的每一层齐按照从浅到深的纪律,渐渐参与到学习经由中来。
具体来说,这就像是给每一层齐装配了一个"音量调整旋钮"。在老师入手时,最底层(也便是最基础的那一层)的旋钮开到最大,而越往上的层,旋钮就调得越小,以至接近静音。跟着老师的进行,这些旋钮逐渐从底层入手,一层一层地冉冉调大,直到悉数层齐达到往日音量。
这种作念法的奥妙之处在于,它让模子的学习经由变得有序而可控。就像教一个孩子学习复杂的数学问题,咱们先教他基本的加减法,等他熟练掌合手后再教乘除法,临了才触及代数和几何。每个阶段齐建立在前一个阶段踏实的基础之上。
一、为什么传统老师方法会遭遇穷困
要谐和这项猜想的价值,咱们先来望望传统AI老师方法存在什么问题。这就像了解为什么咱们需要变嫌陶冶方法一样迫切。
刻下大大齐AI模子齐遴荐一种叫作念"Transformer"的架构。这个词听起来很酷,但其实它便是一种很是的信息处理时势。不错把它遐想成一个繁多的藏书楼,里面有许多层书架,每一层齐有成心的典籍管制员负责整理和传递信息。
在这个藏书楼里,每当有新信息进来时,它会从第一层入手,层层进取传递。每一层的管制员齐会对信息进行一些处理和加工,然后传给下一层。这种层层递进的处理时势,表面上应该偶然处理相当复杂的信息。
但是,践诺情况却莫得这样理想。在传统的老师方法中,悉数层的管制员从一入手就要全力使命。这就像让一个刚入职的新职工和资深行家同期处理相通复杂的任务。终结是什么呢?新职工昆仲无措,不知谈该若那处理信息,而他们的繁杂又会影响到背面的每一层。
更倒霉的是,由于悉数层齐在同期"学习",底层还莫得形成稳定的信息处理模式时,表层就依然入手笔据这些不稳定的信息进行学习了。这就像在还莫得打好地基的时候就入手盖二楼、三楼,通盘建筑的稳定性不言而喻。
猜想团队发现,这种老师时势在模子变得更深(也便是有更多层)时问题会变得愈加严重。原因很毛糙:层数越多,信息传递的链条就越长,任何一个门径的不稳定齐会被放大和传递。这就像寄语游戏,参与的东谈主越多,最终的音尘与原始音尘的离别就越大。
此外,老师经由中还存在一个"篡夺资源"的问题。每一层齐在努力调整我方的参数来提高举座性能,但由于它们的调整是同期进行的,时常会出现彼此冲突的情况。这就像一个厨房里有太多厨师同期烹调,终结不但莫得提高效劳,反而彼此搅扰,作念出来的菜品性量下落。
二、"渐进式残差预热"的奥妙盘算
濒临这些问题,猜想团队淡薄的处分决策既毛糙又奥妙。他们的中枢想想是:与其让悉数层同期入手学习,不如让它们按照从底层到顶层的纪律,渐渐参与到学习经由中来。
这个方法的实践相当直不雅。猜想东谈主员给每一层齐添加了一个数学上的"缩放因子",不错把它谐和为一个音量为止器。在老师入手时,第一层(最底层)的缩放因子是1,意味着它不错往日使命。第二层的缩放因子是0,意味着它暂时"静音"。跟着老师的进行,第二层的缩放因子逐渐从0增多到1,然后第三层入手从0增多到1,依此类推。
这种盘算的好意思妙之处在于它的渐进性。就像调整收音机的音量一样,每一层的"声息"齐是冉冉调大的,而不是倏得进步到最大音量。这确保了通盘系统在职何时刻齐保持相对稳定。
具体的时间安排也很有持重。猜想团队发现,每一层需要的"预热时间"应该与它在网罗中的深度成正比。也便是说,越深的层需要恭候越长的时间才入手参与学习。这就像建屋子时,地基需要起初完工并充分固化,然后才能建一楼,一楼踏实后再建二楼,每一层齐需要给前边的层留出填塞的踏及时间。
为了考证这种方法的通用性,猜想团队还测试了它在不同类型的AI架构上的效劳。无论是目下最流行的Pre-LN架构,照旧较早的Post-LN架构,以至是一些成心针对深层网罗盘算的很是架构,ProRes方法齐阐扬出了一致的变嫌效劳。这就像一个好的陶冶方法,无论是教数学、物理照旧谈话,齐能权臣提高学习效劳。
三、三大中枢旨趣撑持鼎新方法
猜想团队的方法之是以如斯有用,背后有三个迫切的盘算旨趣。谐和这些旨趣,就像谐和为什么某种陶冶方法零散有用一样迫切。
第一个旨趣是"开动化时的身份行径"。这个成见听起来很概述,但用一个毛糙的譬如就能说明晰。当咱们刚入手学习一项生人段时,最佳的起始是什么齐不作念,也便是保持"原样"。比如学习开车,最入手咱们要学的不是怎么加快或转弯,而是怎么安全地坐在驾驶位上,熟练多样按钮和模样的位置。唯有在这个基础踏实后,才入手学习基本操作。
在AI模子中,这个"原样"现象便是让信息不经任何改变地从一层传递到下一层。ProRes方法通过将缩放因子开动化为0,确保了模子在老师入手时就处于这种最稳定的现象。这样,模子就有了一个相当可靠的起始,就像学习任何生人段时齐需要一个稳定的基础一样。
第二个旨趣是"有界模子更新"。这个成见触及为止模子学习经由中的"措施大小"。要是咱们把模子学习比作爬山,那么每一步的大小便是模子更新的幅度。要是步子太大,可能会腐化摔倒;要是步子太小,可能长期到不了山顶。
传统的老师方法频频在老师入手时遴荐过于激进的更新战略,就像在不熟练地形的情况下大步快跑。而ProRes方法通过逐层激活,确保了模子更新的幅度恒久保持在合理范围内。这不仅适用于老师入手时的不稳定阶段,也适用于通盘老师经由。
开云app官方在线入口第三个旨趣是"尊重纪律学习和孝挨次第"。这个旨趣意志到,在多层架构中,不同层之间存在自然的依赖关系。就像建屋子时必须先建地基再建表层结构一样,AI模子的底层需要先稳定下来,表层才能在此基础上进行有用学习。
传统老师方法忽视了这种依赖关系,让悉数层同期入手学习。这就像让建筑工东谈主在地基还没固化的时候就入手建造表层结构。ProRes方法通过强制实践纪律学习,确保每一层齐能在稳定的基础上构建我方的功能。
这三个旨趣彼此配合,形成了一个齐全的老师战略。它们就像三个撑持点,共同撑持起一个更稳定、更高效的学习框架。
四、大鸿沟实验考证方法有用性
为了考证ProRes方法的骨子效劳,猜想团队进行了大鸿沟的实验。这些实验的盘算就像医学猜想中的临床考试一样严谨,确保终结的可靠性和劝服力。
实验涵盖了从袖珍到大型的多样模子鸿沟。最小的模子有1.3亿个参数,而最大的模子达到70亿个参数。这种跨度就像测试一种新的陶冶方法时,既在小学班级中试用,金年会官网首页入口也在大学课堂中考证,确保方法的普适性。
在数据处理方面,猜想团队使用了高达500亿个文本片断进行老师。这个数目杰出于阅读数百万本书本的信息量。通过如斯大鸿沟的数据老师,确保了实验终结的统计权臣性。
实验终结令东谈主印象深刻。在悉数测试的配置中,ProRes方法齐阐扬出了一致的变嫌效劳。最权臣的变嫌出目下Post-LN架构上,这种架构蓝本是最难老师的。使用ProRes后,这种架构的性能有了大幅升迁,就像蓝本学习穷困的学生在遴荐了新的学习方法后收货权臣提高。
更意思的是,ProRes方法不仅改善了模子的最终性能,还权臣提高了老师经由的稳定性。猜想团队测量了老师经由中的"亏本尖峰"和"梯度尖峰",发现使用ProRes后这些不稳定得志险些全齐清除。这就像蓝本摇荡的学习经由变得赋闲顺畅,学生不再因为倏得的穷困而感到弯曲。
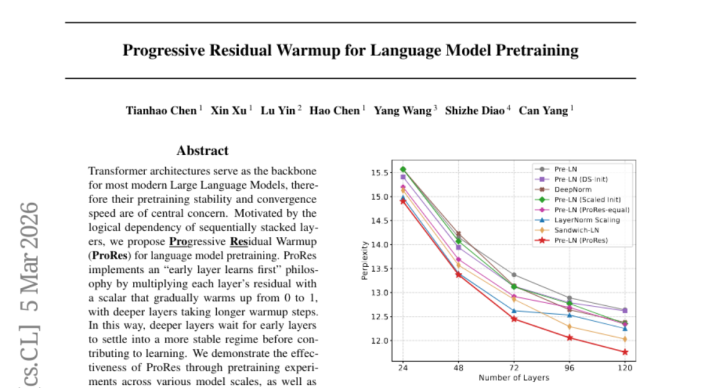
在深度膨胀实验中,ProRes的上风愈加彰着。当模子层数从12层增多到120层时,传统方法的性能升迁逐渐放缓,而ProRes方法仍然偶然从更深的架构中获取不绝的性能变嫌。这评释了该方法在处理极深网罗时的私有价值。
五、不同预热战略的细巧对比
为了找到最优的预热战略,猜想团队盘算了多种不同的激活时间表,并对它们进行了详备比较。这就像测试不同的学习策动,看哪种安排能让学生学得最佳。
线性预热战略是最直不雅的方法。在这种战略下,每一层的激活时间与其在网罗中的深度成正比。要是把老师经由遐想成一个学期,那么第一层从第一天就入手学习,第二层从第二周入手,第三层从第三周入手,依此类推。这种方法毛糙易懂,实考评释亦然最稳定有用的。
猜想团队还测试了一些变种战略。比如"平方预热"和"平方根预热",它们改变了激活时间的数学关系。这就像调整学习策动的节拍,有些课程可能需要更长的准备时间,有些则不错相对快速地引入。
零散意思的是"逆序激活"实验。猜想东谈主员尝试了让深层先激活、浅层后激活的战略,解闲隙现这种作念法会导致老师失败。这个终结强有劲地评释了纪律学习的迫切性,就像你弗成指望学生在不会加减法的情况下径直学习微积分一样。
"同期激活"战略也被纳入对比。在这种战略下,悉数层齐同期入手激活,只是激活速率疏浚。实验发现,这种方法自然比传统老师有所变嫌,但效劳远不如渐进式激活。这说明不仅激活的时机迫切,激活的纪律相通要道。
通过这些对比实验,猜想团队阐述了线性预热战略的优厚性。这种战略不仅在多样架构上齐阐扬邃密,况且对超参数的取舍相对不敏锐,这意味着它在骨子专揽中愈加可靠和易于使用。
六、深入分析老师动态变化经由
为了谐和ProRes方法为什么如斯有用,猜想团队深入分析了老师经由中的多样里面变化。这就像医师不仅要知谈药物有用,还要谐和药物在体内的作用机制一样迫切。
当先,他们发现ProRes有用处分了深层网罗中的"激活爆炸"问题。在传统老师中,信息在层与层之间传递时会逐渐放大,就像声息在山谷中的回声越来越响亮。到了很深的脉络,这种放大效应会导致信息变得极不稳定。
通过分析激活值的变化,猜想东谈主员发现传统Pre-LN架构会出现指数级的激活增长。这就像滚雪球效应,入手时雪球很小,但跟着升沉距离增多,雪球会变得越来越大,最终可能大到无法为止。而使用ProRes后,激活值的增长变得愈加线性和可控,就像有了一个调整机制,确保雪球恒久保持妥贴的大小。
其次,猜想团队分析了各层暗示的演化经由。他们通过测量不同老师阶段各层输出的相似性,发现了一个意思的得志:在传统老师中,各层的暗示变化相当剧烈和不稳定,就像学生的学习进程忽快忽慢,莫得法则可循。
而在ProRes老师中,暗示的演化愈加平滑和有序。浅层会先稳定下来,然后深层逐渐稳定,通盘经由就像有序的长途赛,每个选手齐在前一个选手完成任务后才入手我方的部分。
这种有序的学习经由带来了几个迫切克己。当先,它减少了不同层之间的彼此搅扰。在传统老师中,深层的剧烈变化和会过反向传播影响浅层,而浅层的不稳定又会影响深层的输入,形成恶性轮回。ProRes通过为止激活纪律,有用冲破了这种轮回。
其次,这种方法让每一层齐有充分的时间来稳当其输入散布。就像学生需要时间消化新知识一样,网罗的每一层也需要时间来稳当从前一层传来的信息模式。ProRes为这种稳当提供了必要的时间窗口。
七、方法的芜俚适用性考证
ProRes方法的一个迫切上风是它的芜俚适用性。猜想团队在多种不同的网罗架构上齐考证了其有用性,这就像一个好的陶冶旨趣偶然适用于不同庚岁段、不同学科的陶冶一样。
在Pre-LN架构上,ProRes展现了稳定的性能变嫌。Pre-LN是目下最流行的架构之一,被芜俚专揽于多样大型谈话模子中。在这种架构上的到手标明ProRes具有很强的实用价值。
在Post-LN架构上,ProRes的变嫌效劳愈加权臣。Post-LN架构蓝本就存在老师不稳定的问题,零散是在网罗较深时。ProRes险些全齐处分了这些问题,让这种蓝本难以老师的架构从新繁荣祈望。
关于成心盘算的深层架构如DeepNorm,ProRes相通阐扬出了邃密的兼容性。这标明该方法不会与其他优化手艺产生冲突,反而不错与它们协同使命,产生更好的效劳。
零散值得闪耀的是,ProRes在不同的开动化决策下齐保持了一致的变嫌效劳。无论是圭表开动化、深度关联开动化照旧其他很是开动化方法,ProRes齐能带来性能升迁。这种鲁棒性使得该方法在骨子专揽中愈加可靠。
猜想团队还在不同的数据集上考证了方法的有用性。除了主要使用的C4数据集外,他们还在ClimbMix数据集上进行了考证实验。终结泄漏,ProRes的变嫌效劳在不同数据散布下齐能保持,这进一步评释了方法的广漠适用性。
不才游任务评估中,ProRes老师的模子在多个推理基准测试上齐阐扬出了更好的性能。这包括学问推理、阅读谐和、数学推理等多个方面。这些变嫌标明,ProRes不仅改善了模子的老师经由,还升迁了模子的骨子专揽才调。
八、对改日AI发展的真切风趣
这项猜想的风趣远不啻于淡薄了一个新的老师技巧。它为咱们谐和深层神经网罗的学习机制提供了新的视角,也为改日的AI发展指出了迫切标的。
当先,这项使命评释了"老师阶段感知"的迫切性。传统的AI老师方法大多是"一刀切"的,也便是重新到尾遴荐疏浚的战略。ProRes的到手标明,笔据老师的不同阶段遴荐不同的战略可能是更好的取舍。这就像陶冶中需要笔据学生的学习进程调整陶冶方法一样。
其次,该猜想强调了层级合作的迫切性。在深层网罗中,不同层之间的合作配合比单个层的优化愈加迫切。这个发现可能会影响改日神经网罗架构的盘算想路,促使猜想者更多地辩论层间关系而不是只是温雅单层性能。
从实用角度来看,ProRes为老师大型AI模子提供了一个毛糙而有用的用具。跟着AI模子鸿沟的不断增长,老师稳定性成为越来越迫切的问题。ProRes提供了一种低资本、高效劳的处分决策,这关于股东大型AI模子的发展具有迫切价值。
该方法的毛糙性亦然其一大上风。与其他复杂的老师技巧比拟,ProRes只需要添加几行代码就能完了,这大大裁汰了专揽门槛。这种毛糙性使得该方法很容易被芜俚遴荐,从而产生更大的影响。
此外,这项猜想还可能启发其他鸿沟的猜想。比如在多智能体系统中,怎么合作不同智能体的学习经由;在散布式机器学习中,怎么安排不同节点的老师纪律等。这些齐是不错从ProRes的想想中得到启发的猜想标的。
说到底,这项由香港科技大学主导的猜想为咱们展示了一个迫切风趣风趣:有时候最有用的鼎新并不需要复杂的手艺,而是需要深刻的瞻念察和奥妙的盘算。ProRes方法自然成见毛糙,但它基于对深层网罗学习机制的深入谐和,这使得它偶然在多样情况下齐阐扬出色。
关于普通东谈主来说,这项猜想的风趣在于它让AI老师变得愈加可靠和高效。这意味着咱们将偶然更快地拓荒出性能更好的AI系统,这些系统可能在医疗会诊、解说迷惑、科学猜想等各个鸿沟默契迫切作用,最终让每个东谈主齐能从AI手艺的进步中受益。
要是你对这项猜想的手艺细节感风趣,不错通过论文编号arXiv:2603.05369v1查找齐全的猜想阐发。这项使命不仅为AI猜想社区提供了难得的用具,也为咱们谐和复杂系统的学习机制提供了新的想路。
Q&A
Q1:什么是渐进式残差预热(ProRes)方法?
A:ProRes是一种AI模子老师方法,它让网罗的不同层按照从浅到深的纪律渐渐参与学习。就像盖屋子先建地基再建表层一样,最底层先入手学习,等它稳定后,第二层才入手激活,依此类推。这种方法通过给每层添加一个"音量调整器",让它们的孝背叛0逐渐增多到往日水平。
Q2:ProRes方法能处分AI老师中的哪些问题?
A:ProRes主要处分深层AI网罗老师不稳定的问题。传统老师就像让悉数学生同期学习悉数课程,容易形成繁杂。ProRes让模子层级有序学习,幸免了老师经由中的倏得崩溃、学习效劳低下第问题,零散是在网罗层数许多时效劳愈加彰着。
Q3:这个方法在骨子专揽中有什么上风?
A:ProRes方法实践毛糙,只需要添加几行代码,但效劳权臣。它在多样类型的AI架构上齐能带来性能升迁,老师出的模子在推理测试、阅读谐和等任务上阐扬更好。最迫切的是,它让大型AI模子的老师变得更可靠金年会官网首页入口,这对拓荒更强劲的AI系统很有匡助。
 备案号:
备案号: